Paper ACM Multimedia — 2025
Shotluck Holmes
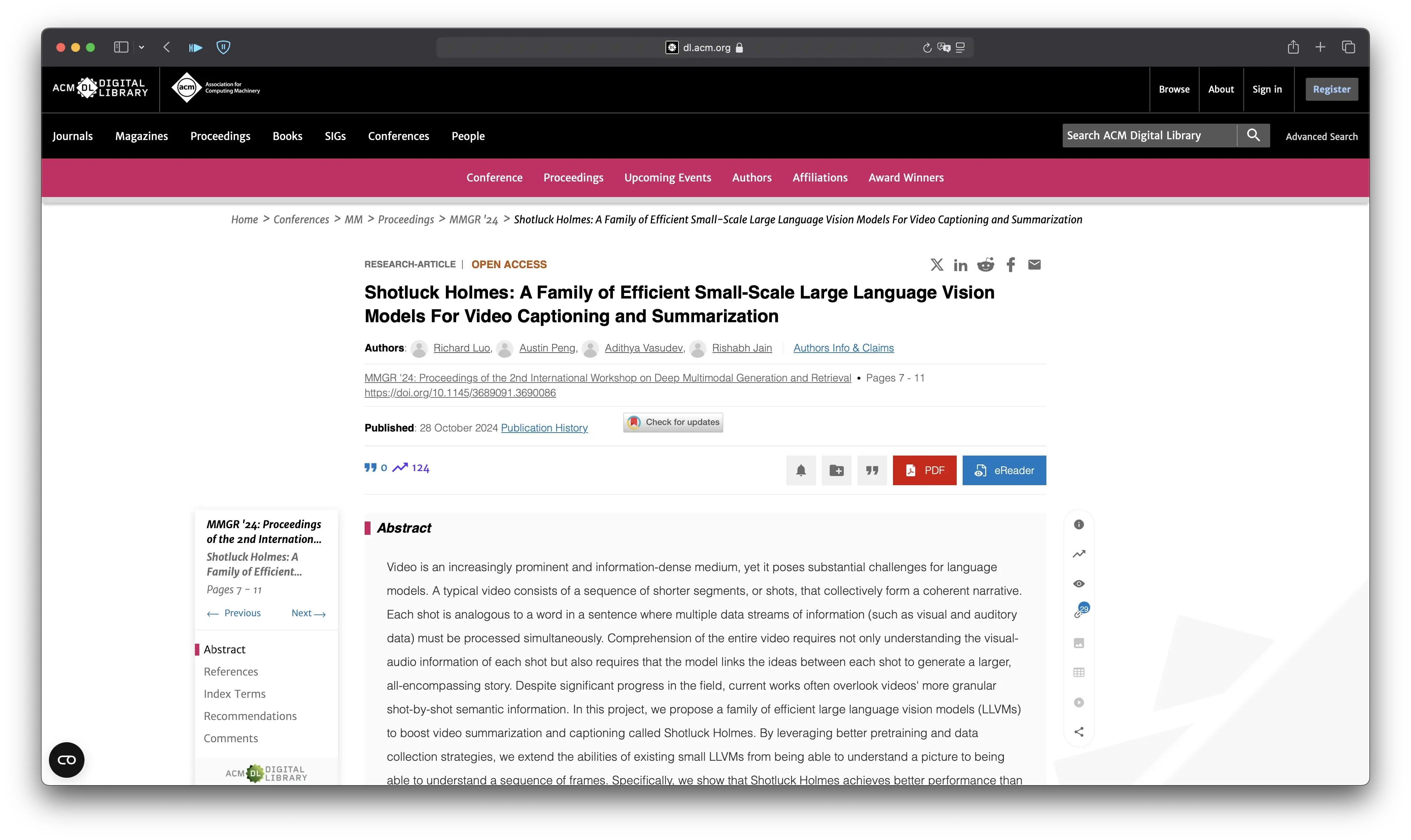
Outperformed prior Shot2Story captioning/summarization baselines with a smaller, compute-efficient shot-aware LLVM. ACM Multimedia 2025.
Multimodal LLMsVideo CaptioningVideo SummarizationPretrainingData Curation
- Shot-level modeling improves narrative coherence across long videos.
- Improved pretraining + data collection to extend small LLVMs from images to frame sequences.
- Strong Shot2Story results without scaling to massive models.
- Focuses on shot-by-shot semantics that many video approaches overlook.
- Benchmarked on Shot2Story to test linking events across shots into a coherent story.